NSCSCC 2023 PUA-MIPS
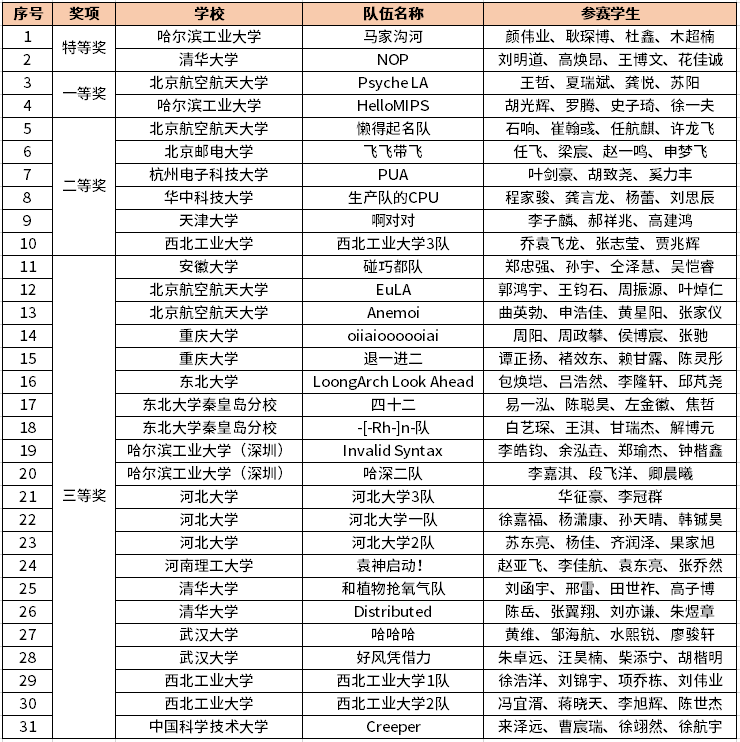
- 杭州电子科技大学第一次参加龙芯杯就拿到二等奖
- 龙芯杯历史上第一次双非学校拿到二等奖
处理器设计不是阳春白雪,不是只有985、211才能参与的多么高深的工作。我相信,在接受了正确的知识之后,哪怕是像我们杭州电子科技大学这样的地方特色高校出来的学生,也能够做出一些有意义的工作,也能够从处理器设计中收获到知识与喜悦。希望更多的人能够参与到处理器设计,能够参与到体系结构的工作中来。
代码仓库
比赛总结
第七届龙芯杯结束了,这应该是历史上第一次有双非院校(除了国科大)拿到龙芯杯的二等奖,事实上,相对于其它的系统设计大赛,龙芯杯的门槛还是比较高的,这次能够拿到二等奖对我们也很意外。
首先,不得不承认的是,这一届在竞争上确实不如上一届的比赛队伍。尽管这一届有更多的队伍实现了诸如乱序双发射,分支预测这样的优秀部件,也有很厉害的队伍突破了性能记录,但是比赛队伍的总体性能分数并没有显著上升,对架构的突破也比较少。
整个比赛对处理器设计的边界效应在加强,想要在架构上做出优化需要非常高的技术水平,而这一届的队伍中,能够做出这样的优化的队伍并不多。
但是,在处理器设计之外,这个比赛能做的事情还有很多。比如,我们的队伍就在这一届的比赛中,做了一些有意义的事情,也发现了一些比较重要的思想指导:
- 我们实现了一些设计空间探索,通过数值模拟的方式,探索了一些处理器设计的边界效应,这些边界效应对于处理器设计的优化有着重要的指导意义。
- 我们基于nemu设计了我们自己的模拟器,这大大提高了我们起Linux的效率。正常设计下,即使是通过verilator仿真器看波形,比对trace,起一个Linux操作系统或许也需要两到三周的时间,我们在nemu的基础上花了一两天简单修改了一下,实现了一个简易Linux模拟器,在半天左右的时间就成功起了Linux。
- 加强方法论的指导。比赛比到最后就是比谁的方法论特色鲜明。哈工大能够在本次比赛刷新性能分记录,取得119分的成绩,是因为他们在最开始就按照工业上实现处理器的方法,也即先实现一个cycle级模拟器,再对这个模拟器进行优化,根据这个模拟器编写RTL代码,这或许是更重要的部分。
- 重视答辩,重视答辩,重视答辩。这一届的答辩,我们的队伍在答辩中表现得非常好,这也是我们能够拿到二等奖的重要原因。
参赛的前置条件
鉴于可能很多人参考我们的过程,我先做一些比赛的前置条件,我们是在这样的基础上进行开发的。
- 队伍至少有一个人参加过“一生一芯”并且通关B线。一生一芯带来的不仅是知识的指导,更重要的是习惯的养成,方法论的指引。如果你没有参加过一生一芯,我建议你至少看一下第五期一生一芯的视频,然后再来参加龙芯杯。对我们来说一生一芯最重要的经验:
- 重视工具:重视模拟器/仿真器,重视trace。
- 不言自证,不证自明。你写出来的代码真的正确吗?如何保证你的代码是和文档描述相符的?
- 数据指导优化。你设计了新的优化部件,你要如何确定它的优化效果?
- 避免过早优化。你的优化是否真的有意义?如果是频率优化,它在关键路径上吗?你是否真的要在现在开始这一步骤的优化?
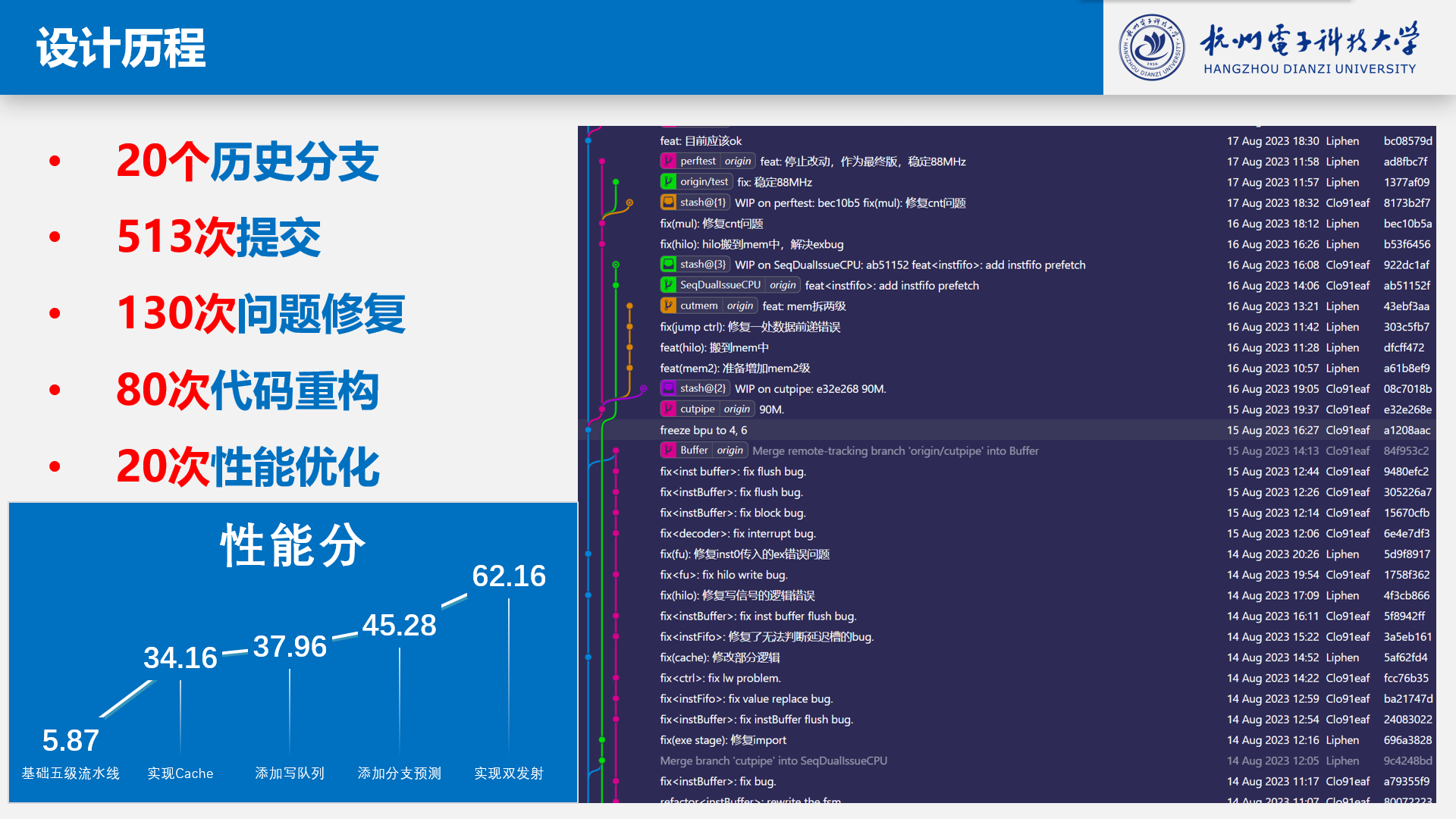
- 提前准备,我们的队伍从3月开始准备,中间除了考试周间断,其它时间基本都泡在实验室里。对于团队赛,你们最好有自己的工作场地,这样才能够保证效率。这个比赛有许多不得不绕的弯路,我们在架构上大重构了五次左右,从openmips到cpu设计实战,从乱序到顺序双发,从集中式控制到分布式握手信号控制。你会面临很多选择,你需要有足够的时间去做这些选择。
知识准备不是特别必要。我们队伍的参赛队员都只有计算机组成原理的知识。(甚至作为队长的我计组考试只有68分)
《CPU设计实战》和《超标量处理器设计》的知识内容一般足够入围决赛。
开发过程
我们从三月份开始准备,一开始看《自己动手写CPU》。这本书被过去的很多队伍推崇,但是从我们实践上来说,这本书写的代码既不灵活,也不易改进。命名混乱,代码风格不统一,很多地方都是硬编码,不利于后续的优化。我们在看完这本书之后,决定更改架构却无从改起。后来果断放弃了这个方案,开始实现《CPU设计实战》。
如果你想要参加这个比赛,跟着《CPU设计实战》一步一步做吧。这本书基本就是为龙芯杯而生的,里面的处理器设计都很符合直觉,而且代码风格也很统一,很容易修改。我们在实现《CPU设计实战》的过程中,也做了一些改进,根据Chisel语言的特性对这本书提到的处理器核的实现做了封装。
实现完《CPU设计实战》后,我们团队犯了一些决策上的错误,我们计划实现乱序,但是乱序带来的复杂度和高延迟让我们不得不放弃从而转向顺序双发射流水线。同时,我们也从往届zenCove的介绍视频中发现乱序带来的性能提升可能是非常有限的(当然,今年乱序的性能分都高的离谱,或许在一定的复杂度之后,乱序也能带来很高的ipc提升)。这里浪费了后端两个月左右的时间。
与此同时,我开始着手优化Cache。为了平衡前端和后端之间的开发速度,我们设计了InstFifo来解耦前后端。在后来我们认为这个部件是我们整个开发过程中做的较为正确的决定。
Cache设计这一块。请务必看一下UltraMIPS_NSCSCC的Cache设计,他们的设计堪称Cache的典范。我们参考了他们的设计,实现了一个性能表现比较好的Cache。Cache的设计使我们的性能分从5分提升到了34分。并且为后续的设计提供了很好的基础。
后面慢慢的根据《超标量处理器设计》就起分支预测,TLB等等,后端就着重于实现功能,优化时序,这部分其实没什么可讲的。细节很多,我们在这一时期设计的代码也比较乱,git切了十几个分支现在也懒得优化了(。
七月份放暑假了就全身心投入在比赛上。主要还是改Cache,优化参数。顺便用用模拟器,为后面起Linux做准备。我们的总的项目代码只有5k行左右,应该在历年的获奖代码中都算比较少的,主要是大量的精简组合逻辑,并且使用一些Chisel的函数式语言特性。我们从amadeus-mips中学了很多。
初赛文档设计我们使用的是typst。具体的初赛报告可以去代码仓库中看。我对Rust语言很喜爱,所以对typst的使用也比较顺手,而且最终typst出来的文档质量很高。往届的很多队伍使用latex,但是我认为写一些小报告,使用latex不是很舒服,我很期待typst能够发展到和latex一较高下的时候。我觉得文档的美观程度也是很加分的一点。
初赛材料交完了就开始着手起Linux,基于模拟器比如cemu或者nemu可以很轻松的将Linux起起来,我们只花了半天时间就改完了CP0可能遇到的问题并且启动了Linux。我很好奇为什么很多队伍都没有起来Linux,我们有很好的工具cemu,并且比赛官方培训也提到了cemu的使用方法,但是很多队伍还是没有起来Linux。我觉得这是一个很大的遗憾,起Linux能够让你对自己的处理器有更深的认识,也是比赛答辩分数很大的一部分,如果没有起来基本就没有二等奖了。感觉还是方法论的问题,很多队伍没有意识到模拟器的重要性。
决赛照常优化。不过初赛到决赛过程中我们做的优化都不尽如人意。我们在频率上的优化很失败,失败到让我们坚定了我们不可能拿二等奖。我们多次拆分流水线失败,不是ipc暴降就是出现了新的关键路径。我尝试将指令队列中延迟槽的部分单独拆出来,但是效果并不好。具体可以看git仓库中的InstBuffer分支。
惊魂两小时
决赛提交前两个小时,我们上板发现功能测试点70有bug。
仿真器上性能测试,功能测试和Linux都能启动。上板通过了性能测试,甚至也启动了Linux,结果功能测试挂了。(启动Linux比功能测试的时钟周期数大得多)。
回滚回滚,回滚到初赛后起Linux的第一个版本,那个时候我们时序优化基本没做,ipc也没改,很多优化都没做。但是也没办法,最后把那个版本交上去了。那个时候我们基本对二等奖不抱希望了。
提交八点截止。
交了,但是很崩溃。那个时候场面很混乱,但是该做的事情都在做。我们的电脑性能一般,三台电脑开着同时跑三个比特流,反复看自己设计的问题,频率改了个保守的85,能交就算成功。
最后也算是交成功了,发现是决赛期间某个优化导致的bug,但是没时间改了,只能交上去了。
决赛
去河南理工参加决赛答辩。第一版PPT自我感觉良好,说了总体架构,然后说一下我们遇到的困难。答辩前一天晚上十一点给指导老师看,直接就被打回来。
没有亮点,全在念教科书上的东西,讲的东西没有亮点,没有创新,底下的老师都对体系结构很清楚,教科书上有的根本没必要讲。而且我们的PPT也不够精简,很多东西都是废话,没有重点。
后来对PPT大刀阔斧的改,改到凌晨一点,第二天早上六点起来(只睡了四个小时。)十点半开始答辩。答辩准备的时候,我们的PPT还在改。稿子也反复琢磨,最后好在是有惊无险。
答辩的过程很顺利。
关于答辩,我的总结就是:
- 数据很重要。
- 体现工作量。
- 体现亮点。
具体的决赛PPT也在仓库doc/slides.pdf中。可以作为参考。我们没有像前面几届的队伍一样先说总体架构,再解释每个架构做了什么什么,中间穿插设计的特殊点,而是直接就把亮点和指导思想放在最前面,这是我们认为我们做的比较成功的地方。
一些思考
- 龙芯杯的测试集限制了一些优化的方向,而且很长时间没有更新了。一个8KB的Cache就能将所有指令吃满,一个2bit分支预测就能有95%的命中率,这都在减少可能的性能优化。
- 更好的学校存在一些“壁垒”:
- 更好的服务器配置CI/CD环境。
- 更好的基础设施(这里非常感谢重庆大学能够将他们的模拟器开源出来,这对我们的开发帮助很大)。
- 学长,老师提供方向上的指导。
- 良好的方法论。(不过这点参加一生一芯就可以做到。)
可以看到,在杭电这样的双非院校,缺少课程建设,缺少有效的组织,缺少奖励机制。参加一生一芯的人也在少数,并不是每个人都有能力去改nemu,也不是每个人都有机会接触体系结构的。
- 体系结构这个方向很好,很有意义,需要更多,更好的人才。但是这个方向的门槛也很高,需要很多的知识储备,需要很多的时间投入。这也是为什么很多人不愿意去做体系结构的原因。
我在学习算法的时候,刚学完贪心就学动态规划。动态规划指出了一个道理:当前最优并不一定就能够达到全局最优。很多人会选择贪心算法,即倾向选择回报率更大的方向。
但是我们既不知道这个方向是否回报率更大,也不知道是否回报率更大就是更优的,甚至,即使当时最优,也未必能够达到人生的最优解,每个人对人生最优解的定义也有不同,人生的最优解也不止一个。如果有人问我,你做这件事有什么好处?我想我大概一时半会也答不上来。如果我要说为国家的芯片事业做贡献,恐怕要被说是伪善之类,如果要我说能拿到很好的offer,我看也未必。
现在想来,学生时代做一些事情还是不要从“好处”的角度出发做事情比较好。这可能是人生中为数不多没有什么负担的做一些“理想主义”的事情的时期。胡伟武老师说,你给国家,给人民带来的好处越多,你给自己带来的好处越多。我大概就是这样想的。
人生就是一个巨大的混沌系统,不如做一些有意义的,不会后悔的事情吧。