
在 CPU 设计中,访存在极大程度上限制着 CPU 的频率增加。读取数据和写入数据的时间往往是计算所占时间的三十倍以上。整个体系结构的研究过程其实就是在不断平衡 CPU 运行速度与访存速度的过程。正因如此,出现了许多体系结构方法,比如 Cache,总线,分支预测。 AXI 总线是被广泛使用的一种总线协议,它具有较强的可拓展性和可兼容性。同时它的复杂程度也比较高。可以说,在设计 CPU 的过程中,实现总线协议是遇到的第一个较为 nontrival 的部分。它的信号和状态机设计错综复杂,要考虑的情况极多。 CPU 设计实战通过多个步骤设计遵循 AXI 总线协议的接口,以降低实现 AXI 总线的复杂度。它将实现 AXI 总线协议的工作划分为三个阶段。本篇文章主要针对的就是这三个阶段。
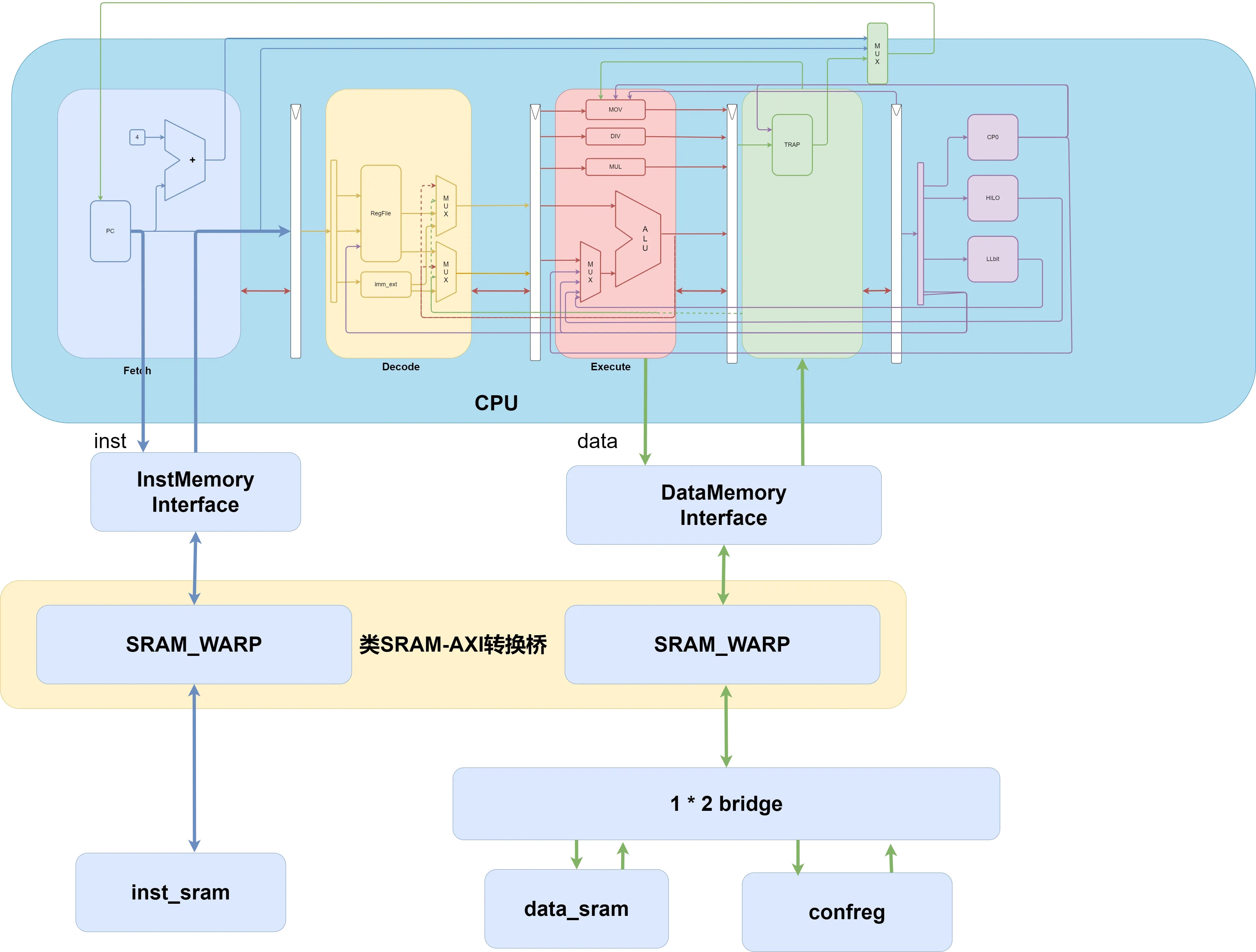
将访问 SRAM 的接口调整为类 SRAM 总线接口
SRAM 可以分为指令 SRAM 和数据 SRAM,数据 SRAM 中又有读和写两个部分。其中读的行为跟指令 SRAM 相差不多。因此,将 SRAM 接口改为类 SRAM 接口的过程主要是针对读取和写入的建模。 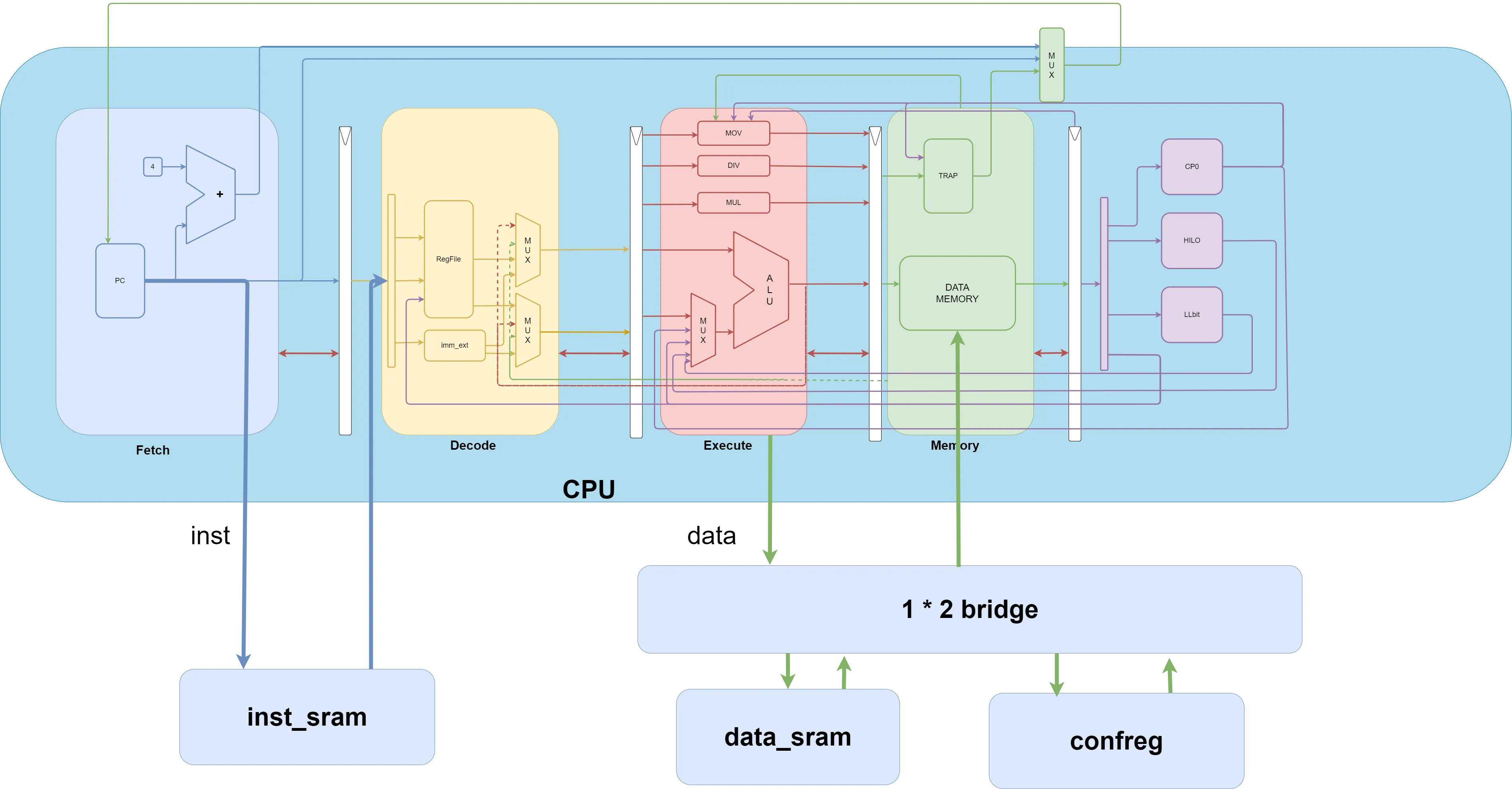
SRAM 总线信号
| 信号 | 位宽 | 方向 | 功能 |
|---|---|---|---|
| en | 1 | master->slave | ram 使能信号 |
| wen | 4 | master->slave | ram 字节写信号 |
| addr | 32 | master->slave | ram 读写地址 |
| wdata | 32 | master->slave | ram 写数据 |
| rdata | 32 | slave->master | ram 读数据 |
类 SRAM 总线接口信号
| 信号 | 位宽 | 方向 | 功能 |
|---|---|---|---|
| req | 1 | master->slave | 1 有读写,0 无读写 |
| wr | 1 | master->slave | 1 写,0 读 |
| size | 2 | master->slave | 本次传输字节数:2^size byte |
| addr | 32 | master->slave | 地址 |
| wstrb | 4 | master->slave | 写请求的字节写 |
| wdata | 32 | master->slave | 写数据 |
| addr_ok | 1 | slave->master | 本次请求的输出传输 ok |
| data_ok | 1 | slave->master | 本次请求的输入传输 ok |
| rdata | 32 | slave->master | 返回数据 |
可以看出,SRAM 比起类 SRAM 总线传输来说信号量更少,也更易理解,因为 SRAM 有许多隐含的规则。比如:当拍发起取指令请求,SRAM 一定要在下一拍返回指令。如果这个返回指令的过程比较长,整个流水线都会卡在这里。由于现阶段我们还没有实现 Cache,所以理所应当的认为每一拍都需要发起取指请求,但是当我们之后实现 Cache 了,许多指令我们都直接从 Cache 中拿,取指只占很少一部分,那时我们不能采用 SRAM 的方式每次都去等那一次取指,我们必须保证流水线”流起来”。 这里我们重新梳理一下为何要使用类 SRAM 总线。主要的原因就是类 SRAM 总线允许 CPU 在不需要访存的时候不会因为去访存而浪费时间。Cache 的实现很大程度上也依赖总线。一言以蔽之,总线将”运算”和”访存”解耦了。
master 向 slave 发送数据,如果 slave 收到数据了,则告诉 master 我收到数据了。因为 master 需要知道 slave 是否因为某些原因不能再接收数据了,来决定 master 是否还需要再发送一次数据。 同样的,slave 也并不是一收到 master 发来的数据,就可以通过这个数据马上执行操作的。最快最快也是在接受到 master 的 addr(wdata)并且返回 addr_ok 的下一拍返回 rdata,这是及其理想的情况,更多的情况是 slave 接受到了 addr,但是没法返回 addr_ok,经过很多拍之后,才最终接受了 addr 并且返回 addr_ok,但是下一拍也没办法直接返回 rdata 和 data_ok,再经过了很多很多拍之后才返回 data_ok。
流水级之间的握手信号
除了访存,CPU 的流水线中还有流水级之间的握手信号。比如取指阶段涉及到 pre fetch stage,fetch stage 和 decoder stage 三个流水级,这三个流水级之间的握手信号是这样的: 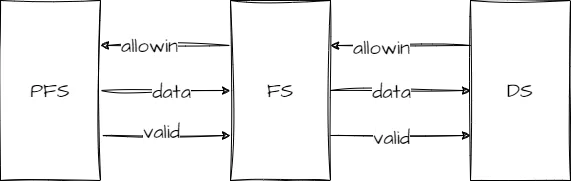
数据可以传输,当且仅当 1。 前一流水级必须准备好数据,此时的数据必须是有意义的(分支预测失败就没意义了)。 2。 后一流水级必须允许前一流水级传输数据。 也就是说,当allowin && valid && ready_go时,上一级数据才能通过一级流水。
| 信号 | 类型 | 含义 |
|---|---|---|
| valid | reg | 当前数据是有效的 |
| allowin | wire | 允许上一级传输数据下来 |
| ready_go | wire | 这一级的数据已经处理完了 |
| X_Y_valid | wire | X 给下一级(Y)的数据是有效的 |
- valid 为什么是寄存器类型? 因为 valid 是流水数据的一部分,在流水线中它和数据一起存在,也正因如此 valid 能代表这一级流水的数据是不是有效的,如果 valid 是线网类型,所有的流水级共用同一个 valid 信号,它什么也代表不了。
- X_Y_valid 有什么用? 考虑这样一种情况:此时流水级的数据已经处理完了,但是发现分支预测错了,意味着这一级流水费劲千辛万苦计算好的信号全都没用,如果这个时候把错误的 valid 传输下去会导致错误的结果。事实上,X_Y_valid 可以使用 valid && ready_go 代替。不仅如此,当考虑例外时,当前的流水级是否需要传递给下一个流水级也跟例外有关,例如,当触发了 ex 例外,流水级停止,那么这时 X_Y_valid 显然要置 false,不能再流下去了。因此,X_Y_valid 单独设置一个信号以更好的维护。
一个比较标准的中间流水级的信号应当是:
// fs.scala
val data = RegInit(0.U(DATA_SIZE.W))
val valid = RegInit(false.B)
val ready_go = a_ok && b_ok && c_ok
val allowin = !valid || ready_go && io.fromds.allowin
val fs_ds_valid = valid && ready_go && !ex && !eret
when(ex || eret) {
valid = false.B
}.elsewhen(allowin) {
valid = io.frompfs.valid
}
when(io.frompfs.valid && allowin) {
data = io.frompfs.data
}
io.ds.valid := fs_ds_validfs(fetch stage)的信号来自 pfs(pre fetch stage),又要流向 ds(decoder stage)。
- 其中 a_ok && b_ok && c_ok 代表这一流水级需要处理的数据。比如在进行乘法运算时,需要运算多拍,那么这几拍 a_ok 都置 false,这个流水级的数据就都没处理好。
- allowin 的写法几乎是固定的,因为它表明这一级流水能不能进来,这级流水能进来有且仅有两种可能:
- 这级流水没用
- 这级流水要流走了
- fs 级给 ds 级的 valid 信号事实上是来自 fs_ds_valid。同样的,io.frompfs.valid 也是来自于 pfs 流水级的 pfs_fs_valid。
- 考虑例外时,例外永远在第一优先级,例外一旦发生,下一拍的数据无效(也就是状态机赋值中
= false.B 的这一行)并且这一级流水的数据也不能给下一级流水。 - data 和 valid 传递的判定条件并不一样。考虑这样一种情况:我这级流水允许上一级流水在下一拍进来,但是上一级流水的数据还没准备好,那我这级流水级下一拍的数据必须得无效。同时,一旦上一级流水准备好了,那上一级数据的 valid 和 data 一块传进来。所以:
when(allowin) {valid = io.frompfs.valid}这行代码其实是这两种情况的综合写法:when(allowin && io.frompfs.valid === false.B) {valid = false.B}when(allowin && io.frompfs.valid === true.B) {valid = true.B}
我们从这四个信号
pfs
pfs 要做的事情就是发请求,所以 pfs 的ready_go = addr_ok,让我们知道 pfs 成功发出请求就行了,同时 pfs 的valid = !reset.asBool,因为它只要复位结束,CPU 开始运行就一直不断取指。allowin 就更加没什么好考虑的了,作为流水级的第一棒,只会产生信号而不会接收信号,因此 allowin 当 true 或者干脆省略就好。同时,我们pfs_fs_valid = ready_go && valid && !ex && !eret,考虑例外是每一个流水级都需要做的事,因此这一赋值也不难理解。
fs
fs 的 valid 来自 pfs,fs 需要接受 inst,因此只有当 inst_ok 时 fs 才算将所有数据都准备好了:ready_go = data_ok。其余的都很常规。
由于我们在实现过程中将 decoder,execute 分为两级,stage 级专门处理流水级之间的数据传递,流水级专注于组合逻辑的事情.因此我们只需要在 stage 级中处理握手协议就行.然而这会带来一些问题,信号都在流水级中产生,比如握手过程中需要用到的 allowin 信号和 valid 信号,因此需要将流水级中产生的信号前向传播到 stage 级.
基本到了这里,流水级之间的握手信号已经说明白了。这些信号虽然多,但是 valid,allowin,X_Y_valid 都是定势,我们需要控制的 ready_go 只要将流水级内部的流水操作模块化,也很容易实现。。。吗?
引入访存之后,所有的复杂度都上了一个等级。需要考虑的事情更多且不易完善。
取值设计
总之,先让我们按照理想的时间详细地分析一下理想的第一条指令取值的时序过程.
- 第一拍
级发出取值地址. - 第二拍:类 sram 总线返回 addr_ok,代表它收到了取值地址.由于收到了 addr_ok,ready_go 判定数据已经准备好了,pfs_fs_valid 为 true.同时准备下一拍的pc(为什么不是这一拍?因为pc是寄存器类型)
- 第三拍:类 sram 总线返回 rdata 和 data_ok,fs 接收 rdata 与 data_ok,由于 pfs_fs_valid,fs 收到来自 pfs 的 pc.因此在这一拍的 pc 和 inst 应该是对应的.
!theme cerulean-outline
hide time-axis
clock "clk" as clk with period 2
binary "rst" as rst
binary "req" as req
concise "addr" as addr
binary "addr_ok" as addr_ok
concise "data" as data
binary "data_ok" as data_ok
concise "pc" as pc
@0
req is 0
addr is {-}
addr_ok is 0
data is {-}
data_ok is 0
pc is {-}
@+1
rst is 1
@+1
req is 1
addr is addr
addr_ok is 1
@+1
addr_ok is 0
data is data
data_ok is 1
@+1
addr_ok is 1
data_ok is 0
@+1
addr_ok is 0
data_ok is 1
@+1
addr_ok is 1
data_ok is 0
@+1
addr_ok is 0
data_ok is 1
@+1
addr_ok is 1
data_ok is 0
@+1
data_ok is 1
addr is {-}
addr_ok is {-}
@+1
data is {-}
data_ok is 0
@3
pc is 0
@+2
pc is 1
@+2
pc is 2
@+2
pc is 3
@+2
pc is {-}
addr@2.5 -> data@3.5TIP在这幅图中省略了size/wstrb/wdata信号,因为它们在我们分析取指行为时序时并不重要.我们在观察波形图时应当着重观察addr_ok/data_ok两个信号,它代表着sram总线的时序.
不理想的情况:
- pfs 发出取值地址.
- 类 sram 总线没有及时返回 addr_ok,导致 ready_go 置 false,此时 pfs_fs_valid 还是 false,pfs-fs 阻塞.
- 类 sram 总线及时返回了 addr_ok,但是 fs 级不允许指令流入,此时
io.fromfs.allowin = false,书中 p191 对这种情况做了详细的说明.这里我们采用问题二的解决思路:我们用一组触发器inst_buff保存取回的指令,并且io.instsram.req = false,这样的话 instsram 就不会返回新的指令.等io.fromfs.allowin === true.B了我们再选择 instbuff 中的指令作为发送给 fs 的指令,此时的 ready_go 是一直置 true 的,所以一旦 allowin 了,fs 就会选择 pfs 中的指令(现在指令来自 inst_buff)传输过去.
考虑转移指令
继续按照时序分析的思路分析一下遇到转移指令时会出现的情况.书本p83:在MIPS指令中,计算跳转目标有一个小陷阱需要注意,请看下面BEQ指令中特殊标记出的两处:转移目标由立即数offset左移2位并进行有符号拓展的值加上该分支指令对应的延迟槽指令的PC计算得到.这句话有点绕,大意就是,beq这条指令,要去的地方,是转移延迟槽,也就是beq指令的后一条指令计算得到. 分支指令在id阶段判断下一条是不是在转移延迟槽中.在将数据传递到ex级的时候通过寄存器打一拍时序可以使得下一条指令在进入ex级时附带is_in_delayslot信号.在我们的设计中,转移指令在id阶段生成br_bus.
- 第一拍:转移指令在fs,ready_go了,转移延迟槽在pfs,它要发送取指请求.
- 第二拍:转移指令到ds,生成br_bus给pfs,要求pfs更新next_pc.此时有两种可能:
- pfs在第一拍发出去的addr收到addr_ok了.pfs的ready_go置true,转移延迟槽成功到达fs,此时pfs可以更新next_pc了.一切正常.
- pfs在第一拍发出去的addr没收到addr_ok,pfs不能流出去,下一拍fsvalid置false,可是此时pfs的next_pc不能因为br_bus而改变.如何判断遇到了这种情况呢?其实也就是:转移指令在ds,fs.valid为false,此时next_pc选转移延迟槽的pc,也就是pc+4.
- 第三拍:继续2.2,此时需要考虑转移指令离开ds的时刻跟在pfs的转移延迟槽收到addr_ok的时刻谁先谁后.
- 转移指令还没离开ds.pfs就收到addr_ok了.pfs的转移延迟槽会在下一拍流向fs,pfs的pc也会在下一拍根据br_bus更新成跳转目的地.一切照常进行,如果转移指令还是在ds,那转移延迟槽就在fs堵着,转移目的地也在fs堵着.如果在后续的某一个时刻,ds通了,但是我们再ds的转移指令向前传递br_bus使用的是组合逻辑,一旦ds通了,pfs的br_bus也就消失了,因此我们必须得把br_bus存起来,等pfs能流走再使用br_bus.br_bus维护了转移目的地,考虑到它可能还得在pfs为了等addr_ok待很长时间,因此br_bus直到转移目的地流走才置无效,期间一直向instsram发送同一个取指请求.
- 转移指令都要离开ds了,pfs还没收到addr_ok.和前一种情况一样,需要用一些寄存器把br_bus存起来.等到pfs收到addr_ok,转移延迟槽进入了fs,下一拍pfs根据br_bus选择next_pc.又过了几拍,转移延迟槽到ds了
- 转移目标的pc还在pfs早已收到addr_ok,一切照常,转移目标到fs级.